


단순 텍스트의 상품 나열이 아닌, web2.0의 개념과 온톨로지 기반으로 탄생한 듯한 오픈마켓이다.
서울의 상권을 중심으로 가상 지도를 만든 후 해당 빌딩에 업체들이 입점을 한다.
입점한 빌딩을 클릭을 하게 되면 그 업체에서 진열하는 제품들이 나온다.
오프라인 쇼핑을 좋아하는 쇼핑족이라면 자신이 찾고자 하는 물건들을
볼거리와 같이 찾을 수 있는 장점이 있다.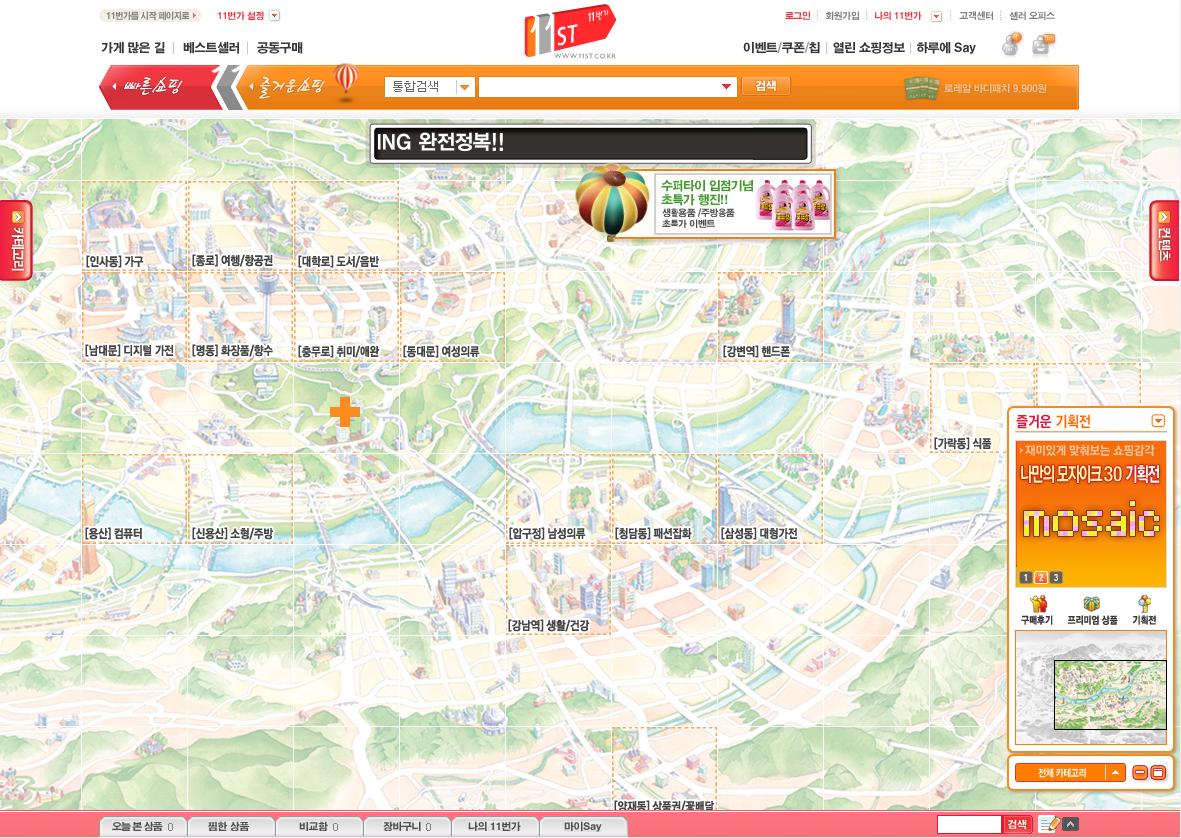
강남역을 클릭시
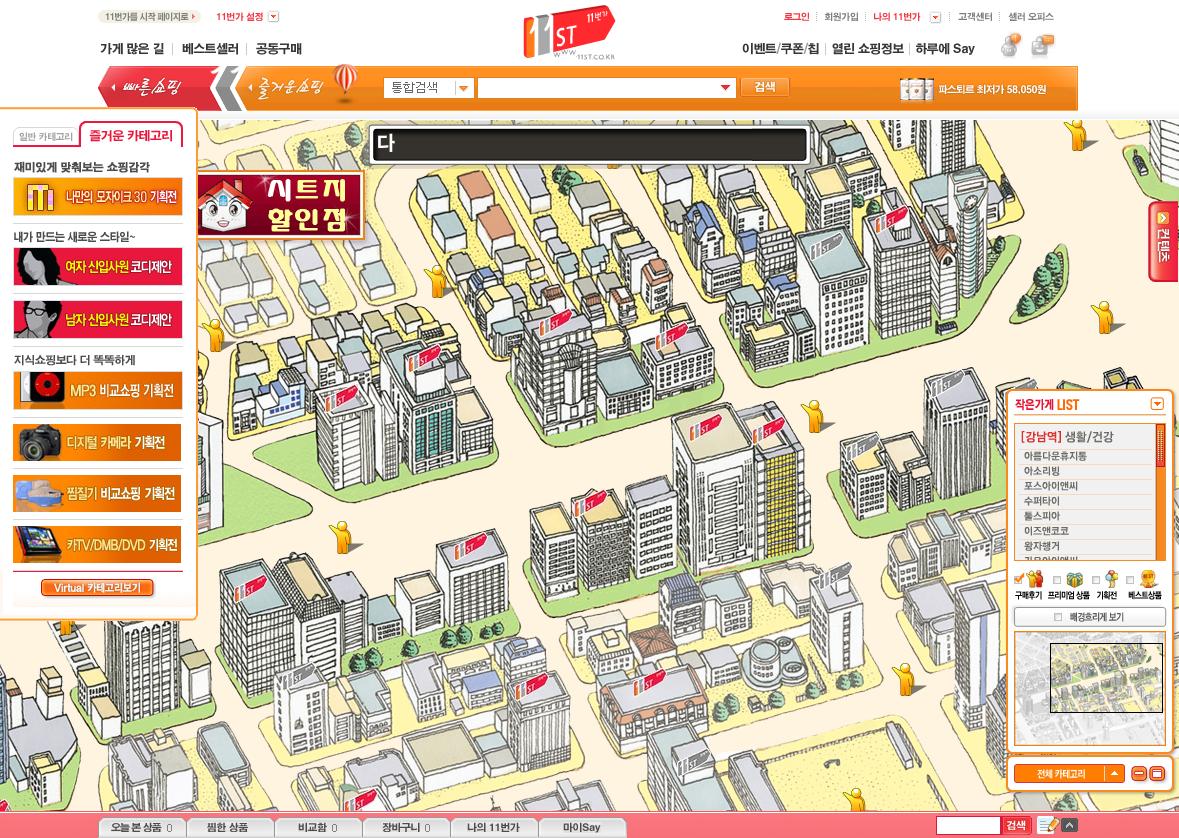
강남역 상권을 2D로 보여주며 쇼핑족들에게 익숙한 환경을 제공한다.
이런 접근은 결국 오프라인의 장점을 온라인에 접목시키겠다는 의도인 거 같다.
그렇담, 오픈마켓의 장점을 포기한 것일까??
아니다. 온라인의 장점은 검색과 온톨로지로 표현한다.
본인이 원하는 상품을 검색 하면 해당 검색어에 대한 관계도를 표현한다.
기존의 오픈마켓은 텍스트로 줄줄이 열거한 거에 비하면 검색 인터페이스에서는
괜찮은 시도로 평가를 하고 싶다.
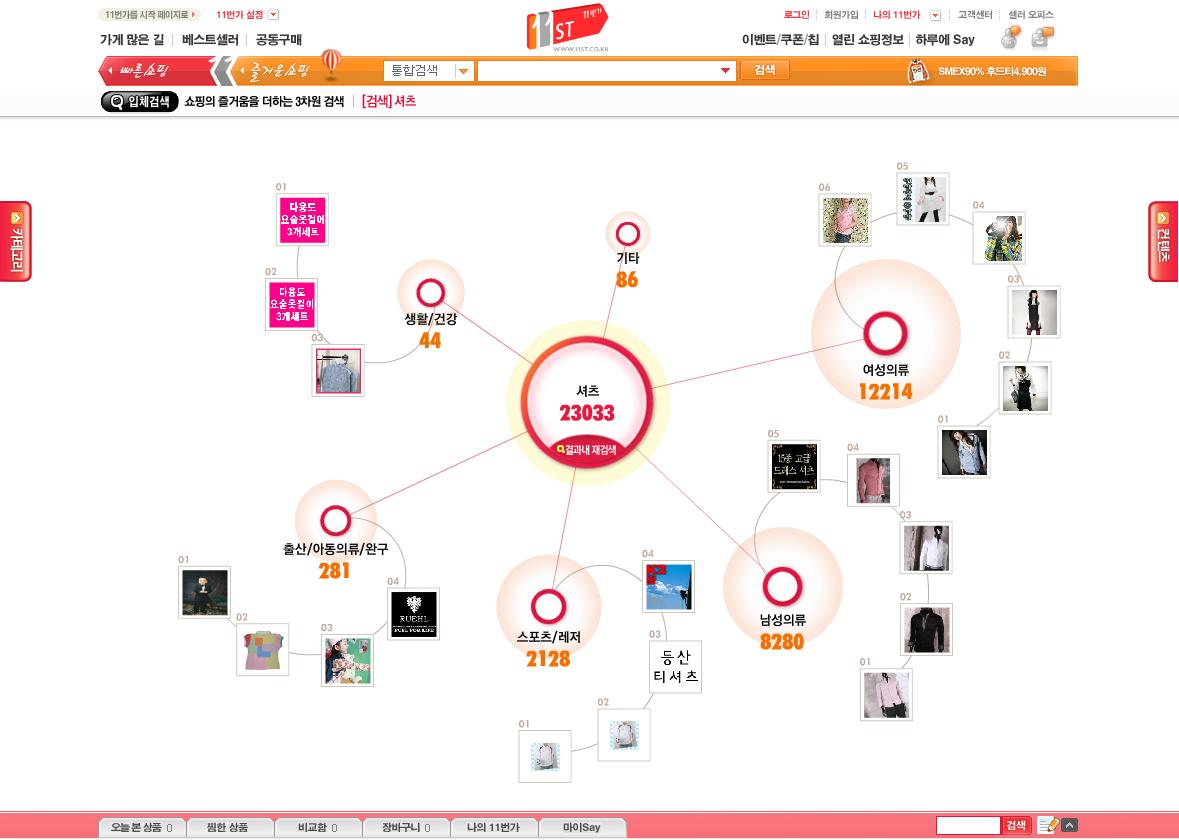
많은 검색 사용자들이 어쩜 단순 텍스트에 식상을 했다고 표현해도 과언은 아니나,
그렇다고 해서 주어진 환경 내에서 다른 인터페이스를 생각한다는 건 그리 만만한 작업이 아니었을 것이다.
이런 시도가 실패로 끝나더라도 검색 결과에 대한 또 다른 인터페이스를 생각케 하는 좋은 결과를
얻을 것으로 판단이 된다.
마지막으로 상품에 대한 배틀이 진행된다.
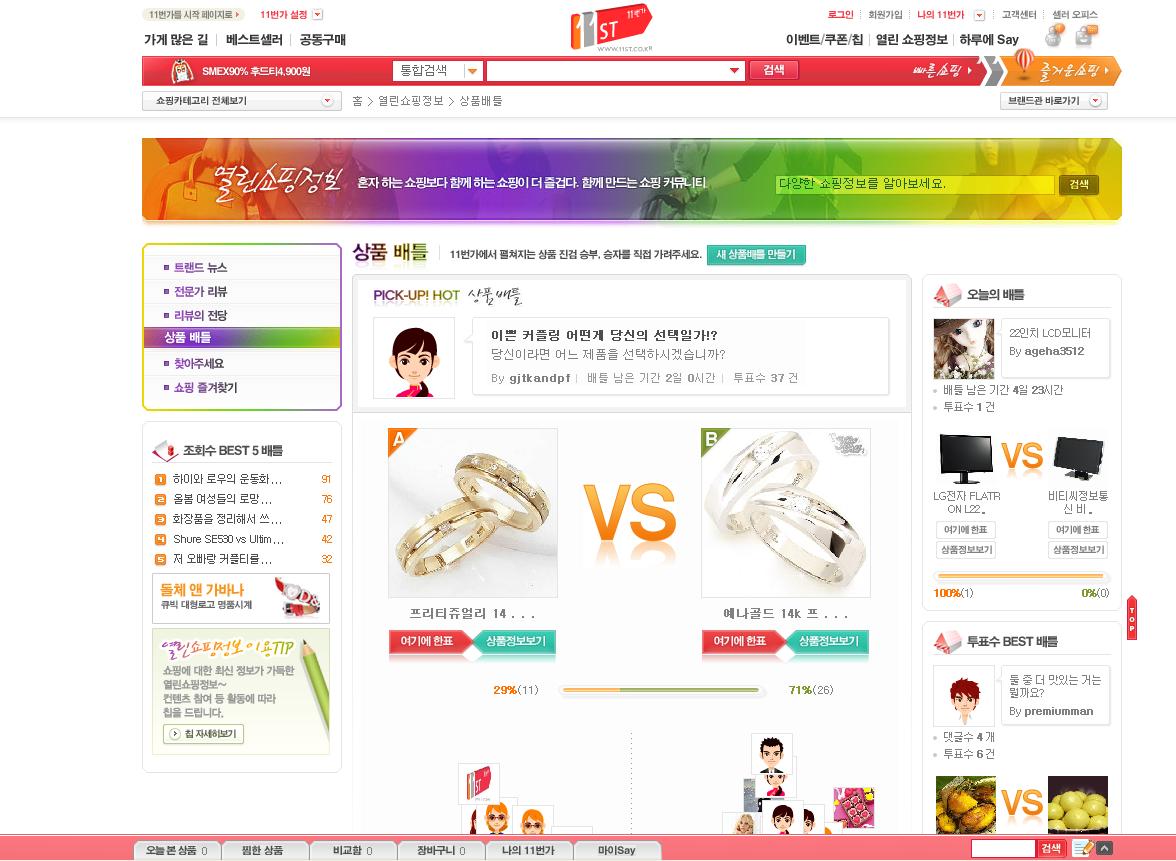
입점한 업체들 간에 굉장히 민감한 사항이 예상이 되나, 좀 더 좋은 가격, 좋은 조건, 좋은 상품을 위해
고객들의 의견을 받아들이는 것 또한 새로운 시도이다.
단순히 특정 상품에 대한 리플로서 그 상품에 대한 평가를 하는 것이 아니라,
MD들의 상품 발굴 및 상품들간의 새로운 평가 기준을 만들 수 있을 것이다.
오픈마켓의 특징을 표출하고자 비교쇼핑 까지 도입이 되었다.
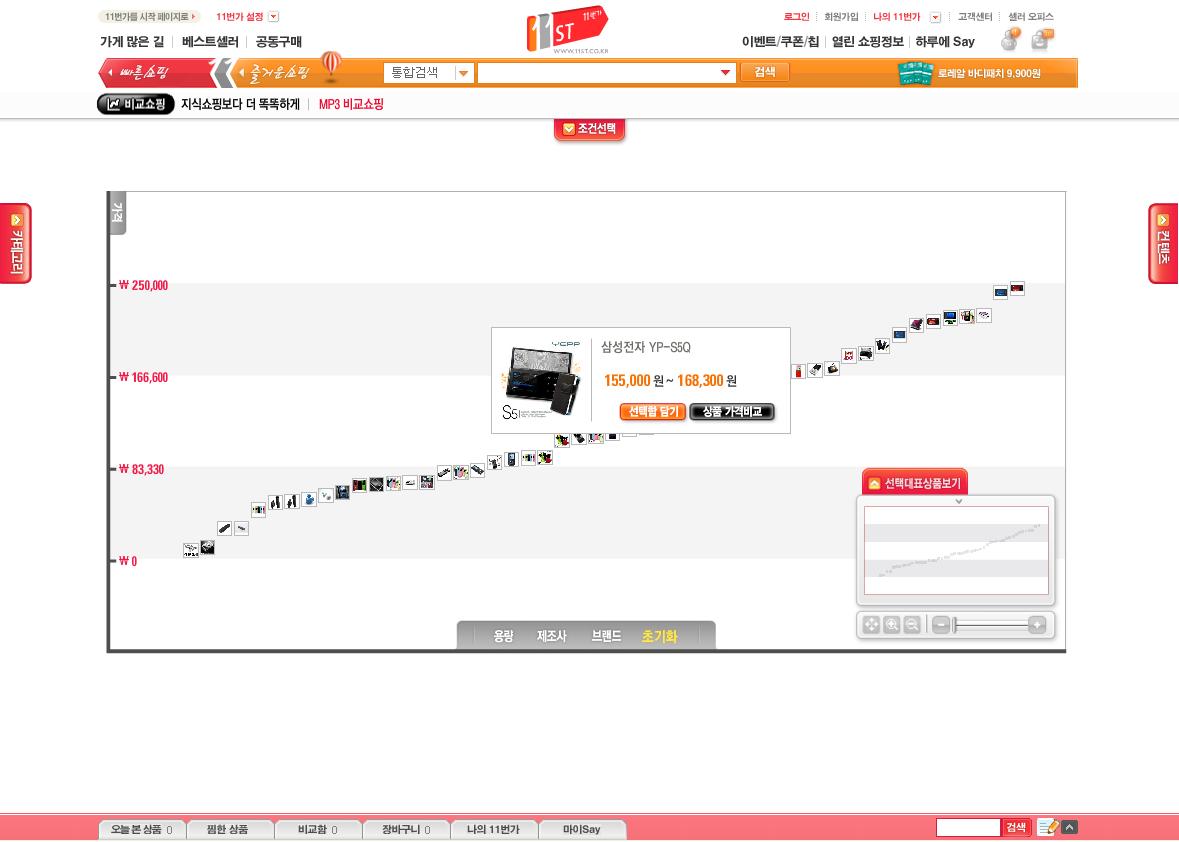
이 또한 단순한 텍스트 나열이 아니라, X, Y 축을 이용한 가격대별로 모델을 표시한 것이다.
이전의 비교쇼핑이라고 하면 주로 같은 상품을 여러 사이트의 가격대를 비교했다면,
이 비교쇼핑은 여러 상품을 가격대별로 눈에 쉽게 들어오는 도표를 활용하였다.
상품에 대한 단순한 텍스트 나열이 아니라
한 눈에 쏘~옥 들어오는 많은 이미지를 사용했으며
검색 인터페이스간의 새로운 가능성을 충분히 보여주었다고 생각한다.
재미와 즐거움이 충분히 느껴진다.~~
서울의 상권을 중심으로 가상 지도를 만든 후 해당 빌딩에 업체들이 입점을 한다.
입점한 빌딩을 클릭을 하게 되면 그 업체에서 진열하는 제품들이 나온다.
오프라인 쇼핑을 좋아하는 쇼핑족이라면 자신이 찾고자 하는 물건들을
볼거리와 같이 찾을 수 있는 장점이 있다.
11번가 메인화면
강남역을 클릭시
강남역 상권을 2D로 보여주며 쇼핑족들에게 익숙한 환경을 제공한다.
이런 접근은 결국 오프라인의 장점을 온라인에 접목시키겠다는 의도인 거 같다.
그렇담, 오픈마켓의 장점을 포기한 것일까??
아니다. 온라인의 장점은 검색과 온톨로지로 표현한다.
본인이 원하는 상품을 검색 하면 해당 검색어에 대한 관계도를 표현한다.
기존의 오픈마켓은 텍스트로 줄줄이 열거한 거에 비하면 검색 인터페이스에서는
괜찮은 시도로 평가를 하고 싶다.
많은 검색 사용자들이 어쩜 단순 텍스트에 식상을 했다고 표현해도 과언은 아니나,
그렇다고 해서 주어진 환경 내에서 다른 인터페이스를 생각한다는 건 그리 만만한 작업이 아니었을 것이다.
이런 시도가 실패로 끝나더라도 검색 결과에 대한 또 다른 인터페이스를 생각케 하는 좋은 결과를
얻을 것으로 판단이 된다.
마지막으로 상품에 대한 배틀이 진행된다.
입점한 업체들 간에 굉장히 민감한 사항이 예상이 되나, 좀 더 좋은 가격, 좋은 조건, 좋은 상품을 위해
고객들의 의견을 받아들이는 것 또한 새로운 시도이다.
단순히 특정 상품에 대한 리플로서 그 상품에 대한 평가를 하는 것이 아니라,
MD들의 상품 발굴 및 상품들간의 새로운 평가 기준을 만들 수 있을 것이다.
오픈마켓의 특징을 표출하고자 비교쇼핑 까지 도입이 되었다.
이 또한 단순한 텍스트 나열이 아니라, X, Y 축을 이용한 가격대별로 모델을 표시한 것이다.
이전의 비교쇼핑이라고 하면 주로 같은 상품을 여러 사이트의 가격대를 비교했다면,
이 비교쇼핑은 여러 상품을 가격대별로 눈에 쉽게 들어오는 도표를 활용하였다.
상품에 대한 단순한 텍스트 나열이 아니라
한 눈에 쏘~옥 들어오는 많은 이미지를 사용했으며
검색 인터페이스간의 새로운 가능성을 충분히 보여주었다고 생각한다.
재미와 즐거움이 충분히 느껴진다.~~
'IT > 검색이야기' 카테고리의 다른 글
| [큐로보] 온톨리지를 기반으로 한 시맨틱웹 검색 (3) | 2008.03.19 |
|---|---|
| [퀸투라] 3세대 검색엔진 (4) | 2008.03.17 |
| [다음 커뮤니케이션]의 자체 검색 엔진 (0) | 2008.03.11 |
| [지도검색] 파란 항공사진 지도 서비스 (0) | 2008.03.07 |
| Future of Internet Search : Mobile version (0) | 2008.03.06 |

쩐의시대
나답게 살아가고 나답게 살아가자



