시맨틱스에서 현재 개발/테스트 중인 Qrobo...
자사 홈페이지에 소개되어 있는 내용을 정리하자면 다음과 같다.
디렉토리 검색엔진은 예전부터 사용해 온 도서 분류학을 모태로 하여 각 홈페이지의 성격을 정하여 사용자의 접근을 좁혀 나가 결국에는 자신이 원하고자 하는 자료를 획득할 수 있었으나,
이젠 하나의 사이트가 하나의 성격을 가지는 것이 아니라, 여러가지 성격을 내포하고 있어
더 이상 구조화된 분류 체계로 표현하기 힘들다.
또한, 200억 페이지 가까이 되는 페이지를 사람(일명 서퍼)들이 일일이 분류하기엔 불가능한 일이다.
키워드 기반 검색엔진은 애매모호성을 띈다.
언어적으로 봤을 경우 하나의 단어가 여러가지 의미를 지니고 있음에도 불구하고
많은 링크가 달렸다는 이유로, 혹은 자주 봤다는 이유로 앞 페이지 대부분을 차지하여
정작 다른 의미의 정보를 원하고자 하여도 한참 뒷 페이지로 넘겨보거나
혹은 확실하지 않은 키워드를 여러개를 나열하여 좁혀 나가야 한다.
그러나, 정보에는 사용자가 원하는 키워드가 표현되지 않았다면 과연 어떻게 찾을까??
그리하여 탄생한 것이 Qrobo 이라고 한다.
검색 엔진 개발에 깊이 참여하고 있는 사람들은 최근 10년 남짓 키워드 기반의 검색엔진에 한계가
있음을 느끼고 있으며, 그렇다고 해서 이것을 뛰어넘는 기술 개발은 아직 많은 시간이 소요된다고 판단하고 있다.
나 또한 검색 엔진 개발만 10년이 넘었지만 쉽지 않은 일임을 잘 알고 있다.
언젠가는 시맨틱스가 지향하고 연구하고 있는 방향은 누군가가 해야할 임에는 분명해 보인다.
그게 1년이 걸리든, 10년이 걸리든...
결국엔 그 방향으로 가야함을 검색 기획자 또한 충분히 동의하는 부분일 것이다.
이런 전제를 놓고 현실의 Qrobo를 보자면 좋은 시도이긴 하나 첫 인상은 실망이다.
일단 시맨틱스가 지향하는 모토는 "사람의 손이 가지 않는 로봇이 만드는 검색엔진"이다.
그래서, 검색 창에 "사람의 손이 가지 않는 로봇이 만드는 검색엔진" 이라고 입력을 해 봤다.
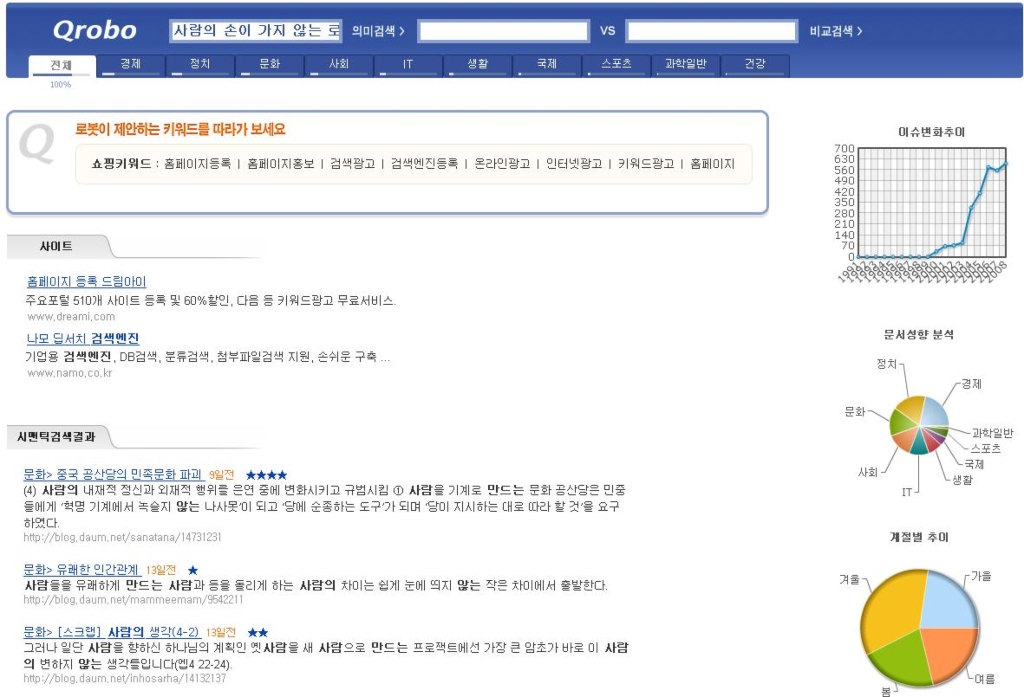
기대감이 컸는지 실망감도 컸었다.
일단, 검색 속도는 둘째 치더라도 결과에 만족스럽지 못하였다.
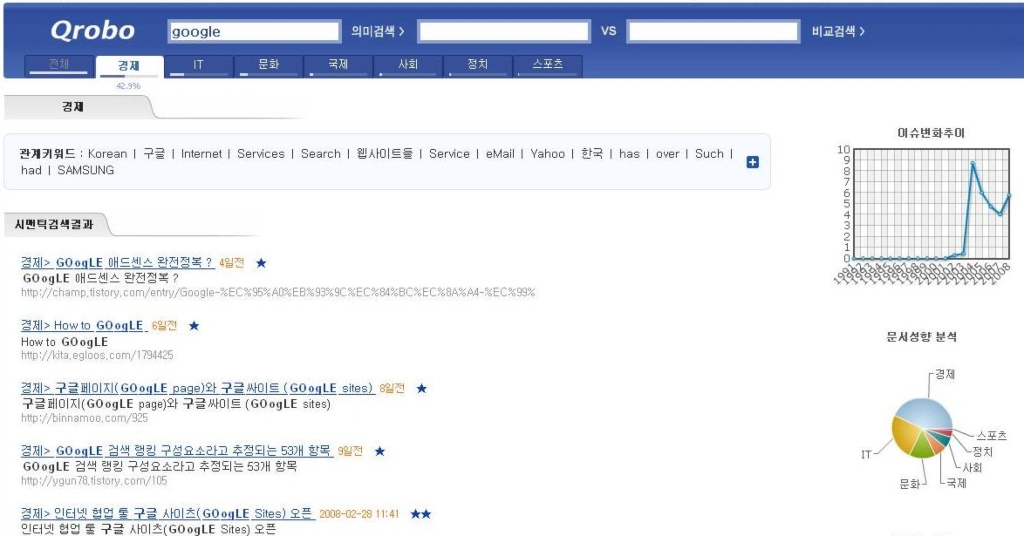
단, 문서성향 분석은 그나마 위안은 된다.
최근의 검색의 추세는 비쥬얼과 시맨틱에는 의심의 여지가 없어 보이나
문서성향 분석은 이미 오래 전에 나왔던 것들이다.
내부적으로 어떻게 구현했는지 잘은 모르겠으나, 겉으로 보이는 모습은 클러스터링이다.
클러스터링과 무슨 차이가 있는지 내부가 궁금해질 뿐이다.
"Google"이라고 검색을 해봐도 별다른 반응을 주지 못할 뿐이다.
관련 키워드들로 정제되지 않은채 그대로 방치된 듯 전혀 키워드로서의 역할을 하지 못하고 있다.
여기에서 관련 키워드들이라고 제시해 놓은 것들 중에 과연 몇 개나 연관도가 높은지 전혀 모르겠다.
오히려 연관도를 잘 나타내고 있는 러시아의 "퀸투라" 엔진이 훨씬 나아 보인다.
이렇게 의외의 결과를 보여주는 것은 이젠 하나의 페이지조차 하나의 성격을 띄고 있지 않다는 것을 간과하지는 않았나 라는 생각이 물씬 풍긴다.
온톨로지를 사용한다는 것은 단어들간의 관계가 잘 정리가 되어야 한다.
이를 바탕으로 추론을 해야 하나 사람이 추론하는 거와는 정말 비교할 수 없는 결과를 낳고 만다.
또한, 온톨로지를 구축한다는 것은 아직은 Vertical한 성격을 지닐 수 밖에 없다.
아무리 기술이 뛰어나다고 해서 이러한 조건을 컴퓨터가 잘 정리할 수 있을까??
정말 사람이 손도 대지 않고 정리가 잘 될까??
아직은 정말 모체에서 갓 태어난 태아 수준이라고 밖에 말할 수 없다.
이러한 관점에서 보자면 시도를 떠나 아직은 실망스럽고 갓 태어난 내 새끼가 사람처럼 보이지 않듯
좀 더 많은 기술과 지식과 추론이 이루어져야 기는 수준이 될 거 같아 보인다.
그러나, 검색엔진...
영어로 그대로 옮기자면 Search Engine이다. 다른 표현으로는 Information Retrieval이다.
디렉토리 검색이든, 키워드 기반 검색이든 Information을 찾는 것이 아니라, data를 찾고 있다.
그 data에서 좀 더 나은 결과를 보여주기 위해 격렬한 전쟁을 벌이고 있으며 이런 전쟁에서 구글이 승자가 되었다.
앞으로는 Information을 찾아주는 시맨틱웹 검색을 취하는 자가 승자가 될 것이다.
나 또한 이런 시도에 대해서는 대만족이며, 나 또한 온톨로지와 검색엔진과의 결합을 고민하고 있으며
감성 또한 심어 보고자 노력하고 있는 중이다.
앞으로 시맨틱스의 도전과 과정을 지켜보고 싶다.



 invalid-file
invalid-file